[arch-commits] Commit in wxmaxima/trunk (PKGBUILD wxmaxima-locale.patch)
Antonio Rojas
arojas at archlinux.org
Sun Jan 3 21:50:10 UTC 2021
Date: Sunday, January 3, 2021 @ 21:50:10
Author: arojas
Revision: 405215
Update to 20.12.2
Modified:
wxmaxima/trunk/PKGBUILD
Deleted:
wxmaxima/trunk/wxmaxima-locale.patch
-----------------------+
PKGBUILD | 10
wxmaxima-locale.patch | 1455 ------------------------------------------------
2 files changed, 3 insertions(+), 1462 deletions(-)
Modified: PKGBUILD
===================================================================
--- PKGBUILD 2021-01-03 18:34:21 UTC (rev 405214)
+++ PKGBUILD 2021-01-03 21:50:10 UTC (rev 405215)
@@ -3,7 +3,7 @@
# Contributor: Vinay S Shastry <vinayshastry at gmail.com>
pkgname=wxmaxima
-pkgver=20.11.1
+pkgver=20.12.2
pkgrel=1
pkgdesc="A wxWidgets GUI for the computer algebra system Maxima"
arch=('x86_64')
@@ -11,15 +11,11 @@
license=('GPL2')
depends=('maxima' 'wxgtk3' 'ttf-linux-libertine')
makedepends=('cmake')
-source=($pkgname-$pkgver.tar.gz::"https://github.com/wxMaxima-developers/wxmaxima/archive/Version-${pkgver}.tar.gz"
- wxmaxima-locale.patch)
-sha256sums=('b1c480d2658ef8483c495ba0d5f29cb14c11654fe49ef44d01508e2d94217a2b'
- '40de6f802b6ba2bc25dc76b42a574c23e992832be61a4af8f23b452fd6f09e79')
+source=($pkgname-$pkgver.tar.gz::"https://github.com/wxMaxima-developers/wxmaxima/archive/Version-${pkgver}.tar.gz")
+sha256sums=('7d2ecf6a19e3ba0f6d3889c1855a85884b71365f5844003c7f3c996e2967d65e')
prepare() {
mkdir -p build
-
- patch -d $pkgname-Version-$pkgver -p1 -i ../wxmaxima-locale.patch # Fix crash when en_US.UTF-8 locale is not enabled
}
build() {
Deleted: wxmaxima-locale.patch
===================================================================
--- wxmaxima-locale.patch 2021-01-03 18:34:21 UTC (rev 405214)
+++ wxmaxima-locale.patch 2021-01-03 21:50:10 UTC (rev 405215)
@@ -1,1455 +0,0 @@
-From 05e417fd71c165ce129ac04d22e280f39f87fa8a Mon Sep 17 00:00:00 2001
-From: Kuba Ober <kuba at bertec.com>
-Date: Sat, 28 Nov 2020 00:30:03 -0500
-Subject: [PATCH 1/4] Import utf-cpp v2.2.1
-
----
- src/ww898/LICENSE.md | 21 +++
- src/ww898/README.md | 58 ++++++++
- src/ww898/cp_utf16.hpp | 109 +++++++++++++++
- src/ww898/cp_utf32.hpp | 67 +++++++++
- src/ww898/cp_utf8.hpp | 158 +++++++++++++++++++++
- src/ww898/cp_utfw.hpp | 47 +++++++
- src/ww898/url.md | 1 +
- src/ww898/utf_config.hpp | 41 ++++++
- src/ww898/utf_converters.hpp | 256 +++++++++++++++++++++++++++++++++++
- src/ww898/utf_selector.hpp | 54 ++++++++
- src/ww898/utf_sizes.hpp | 136 +++++++++++++++++++
- 11 files changed, 948 insertions(+)
- create mode 100644 src/ww898/LICENSE.md
- create mode 100644 src/ww898/README.md
- create mode 100644 src/ww898/cp_utf16.hpp
- create mode 100644 src/ww898/cp_utf32.hpp
- create mode 100644 src/ww898/cp_utf8.hpp
- create mode 100644 src/ww898/cp_utfw.hpp
- create mode 100644 src/ww898/url.md
- create mode 100644 src/ww898/utf_config.hpp
- create mode 100644 src/ww898/utf_converters.hpp
- create mode 100644 src/ww898/utf_selector.hpp
- create mode 100644 src/ww898/utf_sizes.hpp
-
-diff --git a/src/ww898/LICENSE.md b/src/ww898/LICENSE.md
-new file mode 100644
-index 000000000..c807a4214
---- /dev/null
-+++ b/src/ww898/LICENSE.md
-@@ -0,0 +1,21 @@
-+MIT License
-+
-+Copyright (c) 2017 Mikhail Pilin
-+
-+Permission is hereby granted, free of charge, to any person obtaining a copy
-+of this software and associated documentation files (the "Software"), to deal
-+in the Software without restriction, including without limitation the rights
-+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-+copies of the Software, and to permit persons to whom the Software is
-+furnished to do so, subject to the following conditions:
-+
-+The above copyright notice and this permission notice shall be included in all
-+copies or substantial portions of the Software.
-+
-+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-+SOFTWARE.
-diff --git a/src/ww898/README.md b/src/ww898/README.md
-new file mode 100644
-index 000000000..bbb2c22eb
---- /dev/null
-+++ b/src/ww898/README.md
-@@ -0,0 +1,58 @@
-+# UTF-8/16/32 C++ library
-+This is the C++11 template based header only library under Windows/Linux/MacOs to convert UFT-8/16/32 symbols and strings. The library transparently support `wchar_t` as UTF-16 for Windows and UTF-32 for Linux and MacOs.
-+
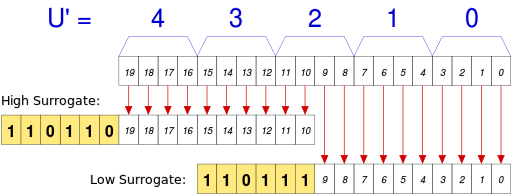
-+UTF-8 and UTF-32 (UCS-32) both support 31 bit wide code points `[0‥0x7FFFFFFF]`with no restriction. UTF-16 supports only unicode code points `[0‥0x10FFFF]`, where high `[0xD800‥0xDBFF]` and low `[0xDC00‥0xDFFF]` surrogate regions are prohibited.
-+
-+The maximum UTF-16 symbol size is 2 words (4 bytes, both words should be in the surrogate region). UFT-32 (UCS-32) is always 1 word (4 bytes). UTF-8 has the maximum symbol size (see [conversion table](#utf-8-conversion-table) for details):
-+- 4 bytes for unicode code points
-+- 6 bytes for 31bit code points
-+
-+###### UTF-16 surrogate decoder:
-+|High\Low|DC00|DC01|…|DFFF|
-+|:-:|:-:|:-:|:-:|:-:|
-+|**D800**|010000|010001|…|0103FF|
-+|**D801**|010400|010401|…|0107FF|
-+|**⋮**|⋮|⋮|⋱|⋮|
-+|**DBFF**|10FC00|10FC01|…|10FFFF|
-+
-+
-+
-+## Supported compilers
-+
-+Tested on following compilers:
-+- [Visual Studio 2013 v12.0.40629.00 Update 5](perf/vc120_win.md)
-+- [Visual Studio 2015 v14.0.25431.01 Update 3](perf/vc140_win.md)
-+- [Visual Studio 2017 v15.6.7](perf/vc141_win.md)
-+- [Visual Studio 2019 v16.0.3](perf/vc142_win.md)
-+- [GNU v5.4.0](perf/gnu_linux.md)
-+- [Clang v6.0.1](perf/clang_linux.md)
-+- [Apple Clang v10.0.1](perf/clang_mac.md)
-+
-+## Usage example
-+
-+```cpp
-+ // यूनिकोड
-+ static char const u8s[] = "\xE0\xA4\xAF\xE0\xA5\x82\xE0\xA4\xA8\xE0\xA4\xBF\xE0\xA4\x95\xE0\xA5\x8B\xE0\xA4\xA1";
-+ using namespace ww898::utf;
-+ std::u16string u16;
-+ convz<utf_selector_t<decltype(*u8s)>, utf16>(u8s, std::back_inserter(u16));
-+ std::u32string u32;
-+ conv<utf16, utf_selector_t<decltype(u32)::value_type>>(u16.begin(), u16.end(), std::back_inserter(u32));
-+ std::vector<char> u8;
-+ convz<utf32, utf8>(u32.data(), std::back_inserter(u8));
-+ std::wstring uw;
-+ conv<utf8, utfw>(u8s, u8s + sizeof(u8s), std::back_inserter(uw));
-+ auto u8r = conv<char>(uw);
-+ auto u16r = conv<char16_t>(u16);
-+ auto uwr = convz<wchar_t>(u8s);
-+
-+ auto u32r = conv<char32_t>(std::string_view(u8r.data(), u8r.size())); // C++17 only
-+
-+ static_assert(std::is_same<utf_selector<decltype(*u8s)>, utf_selector<decltype(u8)::value_type>>::value, "Fail");
-+ static_assert(
-+ std::is_same<utf_selector_t<decltype(u16)::value_type>, utf_selector_t<decltype(uw)::value_type>>::value !=
-+ std::is_same<utf_selector_t<decltype(u32)::value_type>, utf_selector_t<decltype(uw)::value_type>>::value, "Fail");
-+```
-+
-+## UTF-8 Conversion table
-+
-diff --git a/src/ww898/cp_utf16.hpp b/src/ww898/cp_utf16.hpp
-new file mode 100644
-index 000000000..2e1134974
---- /dev/null
-+++ b/src/ww898/cp_utf16.hpp
-@@ -0,0 +1,109 @@
-+/*
-+ * MIT License
-+ *
-+ * Copyright (c) 2017-2019 Mikhail Pilin
-+ *
-+ * Permission is hereby granted, free of charge, to any person obtaining a copy
-+ * of this software and associated documentation files (the "Software"), to deal
-+ * in the Software without restriction, including without limitation the rights
-+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-+ * copies of the Software, and to permit persons to whom the Software is
-+ * furnished to do so, subject to the following conditions:
-+ *
-+ * The above copyright notice and this permission notice shall be included in all
-+ * copies or substantial portions of the Software.
-+ *
-+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-+ * SOFTWARE.
-+ */
-+
-+#pragma once
-+
-+#include <cstdint>
-+#include <stdexcept>
-+
-+namespace ww898 {
-+namespace utf {
-+
-+// 1 0
-+// 98765432109876543210
-+// ||||||||||||||||||||
-+// 110110xxxxxxxxxx|||||||||| high surrogate
-+// 110111xxxxxxxxxx low surrogate
-+struct utf16 final
-+{
-+ static size_t const max_unicode_symbol_size = 2;
-+ static size_t const max_supported_symbol_size = max_unicode_symbol_size;
-+
-+ static uint32_t const max_supported_code_point = 0x10FFFF;
-+
-+ using char_type = uint16_t;
-+
-+ static char_type const min_surrogate = 0xD800;
-+ static char_type const max_surrogate = 0xDFFF;
-+
-+ static char_type const min_surrogate_high = 0xD800;
-+ static char_type const max_surrogate_high = 0xDBFF;
-+
-+ static char_type const min_surrogate_low = 0xDC00;
-+ static char_type const max_surrogate_low = 0xDFFF;
-+
-+ template<typename PeekFn>
-+ static size_t char_size(PeekFn && peek_fn)
-+ {
-+ char_type const ch0 = std::forward<PeekFn>(peek_fn)();
-+ if (ch0 < 0xD800) // [0x0000‥0xD7FF]
-+ return 1;
-+ if (ch0 < 0xDC00) // [0xD800‥0xDBFF] [0xDC00‥0xDFFF]
-+ return 2;
-+ if (ch0 < 0xE000)
-+ throw std::runtime_error("The high utf16 surrogate char is expected");
-+ // [0xE000‥0xFFFF]
-+ return 1;
-+ }
-+
-+ template<typename ReadFn>
-+ static uint32_t read(ReadFn && read_fn)
-+ {
-+ char_type const ch0 = read_fn();
-+ if (ch0 < 0xD800) // [0x0000‥0xD7FF]
-+ return ch0;
-+ if (ch0 < 0xDC00) // [0xD800‥0xDBFF] [0xDC00‥0xDFFF]
-+ {
-+ char_type const ch1 = read_fn(); if (ch1 >> 10 != 0x37) throw std::runtime_error("The low utf16 surrogate char is expected");
-+ return (ch0 << 10) + ch1 - 0x35FDC00;
-+ }
-+ if (ch0 < 0xE000)
-+ throw std::runtime_error("The high utf16 surrogate char is expected");
-+ // [0xE000‥0xFFFF]
-+ return ch0;
-+ }
-+
-+ template<typename WriteFn>
-+ static void write(uint32_t const cp, WriteFn && write_fn)
-+ {
-+ if (cp < 0xD800) // [0x0000‥0xD7FF]
-+ write_fn(static_cast<char_type>(cp));
-+ else if (cp < 0x10000)
-+ {
-+ if (cp < 0xE000)
-+ throw std::runtime_error("The utf16 code point can not be in surrogate range");
-+ // [0xE000‥0xFFFF]
-+ write_fn(static_cast<char_type>(cp));
-+ }
-+ else if (cp < 0x110000) // [0xD800‥0xDBFF] [0xDC00‥0xDFFF]
-+ {
-+ write_fn(static_cast<char_type>(0xD7C0 + (cp >> 10 )));
-+ write_fn(static_cast<char_type>(0xDC00 + (cp & 0x3FF)));
-+ }
-+ else
-+ throw std::runtime_error("Too large the utf16 code point");
-+ }
-+};
-+
-+}}
-diff --git a/src/ww898/cp_utf32.hpp b/src/ww898/cp_utf32.hpp
-new file mode 100644
-index 000000000..90b11fad7
---- /dev/null
-+++ b/src/ww898/cp_utf32.hpp
-@@ -0,0 +1,67 @@
-+/*
-+ * MIT License
-+ *
-+ * Copyright (c) 2017-2019 Mikhail Pilin
-+ *
-+ * Permission is hereby granted, free of charge, to any person obtaining a copy
-+ * of this software and associated documentation files (the "Software"), to deal
-+ * in the Software without restriction, including without limitation the rights
-+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-+ * copies of the Software, and to permit persons to whom the Software is
-+ * furnished to do so, subject to the following conditions:
-+ *
-+ * The above copyright notice and this permission notice shall be included in all
-+ * copies or substantial portions of the Software.
-+ *
-+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-+ * SOFTWARE.
-+ */
-+
-+#pragma once
-+
-+#include <cstdint>
-+#include <stdexcept>
-+
-+namespace ww898 {
-+namespace utf {
-+
-+struct utf32 final
-+{
-+ static size_t const max_unicode_symbol_size = 1;
-+ static size_t const max_supported_symbol_size = 1;
-+
-+ static uint32_t const max_supported_code_point = 0x7FFFFFFF;
-+
-+ using char_type = uint32_t;
-+
-+ template<typename PeekFn>
-+ static size_t char_size(PeekFn &&)
-+ {
-+ return 1;
-+ }
-+
-+ template<typename ReadFn>
-+ static uint32_t read(ReadFn && read_fn)
-+ {
-+ char_type const ch = std::forward<ReadFn>(read_fn)();
-+ if (ch < 0x80000000)
-+ return ch;
-+ throw std::runtime_error("Too large utf32 char");
-+ }
-+
-+ template<typename WriteFn>
-+ static void write(uint32_t const cp, WriteFn && write_fn)
-+ {
-+ if (cp < 0x80000000)
-+ std::forward<WriteFn>(write_fn)(static_cast<char_type>(cp));
-+ else
-+ throw std::runtime_error("Too large utf32 code point");
-+ }
-+};
-+
-+}}
-diff --git a/src/ww898/cp_utf8.hpp b/src/ww898/cp_utf8.hpp
-new file mode 100644
-index 000000000..7c8c68d03
---- /dev/null
-+++ b/src/ww898/cp_utf8.hpp
-@@ -0,0 +1,158 @@
-+/*
-+ * MIT License
-+ *
-+ * Copyright (c) 2017-2019 Mikhail Pilin
-+ *
-+ * Permission is hereby granted, free of charge, to any person obtaining a copy
-+ * of this software and associated documentation files (the "Software"), to deal
-+ * in the Software without restriction, including without limitation the rights
-+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-+ * copies of the Software, and to permit persons to whom the Software is
-+ * furnished to do so, subject to the following conditions:
-+ *
-+ * The above copyright notice and this permission notice shall be included in all
-+ * copies or substantial portions of the Software.
-+ *
-+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-+ * SOFTWARE.
-+ */
-+
-+#pragma once
-+
-+#include <cstdint>
-+#include <stdexcept>
-+
-+namespace ww898 {
-+namespace utf {
-+
-+// Supported combinations:
-+// 0xxx_xxxx
-+// 110x_xxxx 10xx_xxxx
-+// 1110_xxxx 10xx_xxxx 10xx_xxxx
-+// 1111_0xxx 10xx_xxxx 10xx_xxxx 10xx_xxxx
-+// 1111_10xx 10xx_xxxx 10xx_xxxx 10xx_xxxx 10xx_xxxx
-+// 1111_110x 10xx_xxxx 10xx_xxxx 10xx_xxxx 10xx_xxxx 10xx_xxxx
-+struct utf8 final
-+{
-+ static size_t const max_unicode_symbol_size = 4;
-+ static size_t const max_supported_symbol_size = 6;
-+
-+ static uint32_t const max_supported_code_point = 0x7FFFFFFF;
-+
-+ using char_type = uint8_t;
-+
-+ template<typename PeekFn>
-+ static size_t char_size(PeekFn && peek_fn)
-+ {
-+ char_type const ch0 = std::forward<PeekFn>(peek_fn)();
-+ if (ch0 < 0x80) // 0xxx_xxxx
-+ return 1;
-+ if (ch0 < 0xC0)
-+ throw std::runtime_error("The utf8 first char in sequence is incorrect");
-+ if (ch0 < 0xE0) // 110x_xxxx 10xx_xxxx
-+ return 2;
-+ if (ch0 < 0xF0) // 1110_xxxx 10xx_xxxx 10xx_xxxx
-+ return 3;
-+ if (ch0 < 0xF8) // 1111_0xxx 10xx_xxxx 10xx_xxxx 10xx_xxxx
-+ return 4;
-+ if (ch0 < 0xFC) // 1111_10xx 10xx_xxxx 10xx_xxxx 10xx_xxxx 10xx_xxxx
-+ return 5;
-+ if (ch0 < 0xFE) // 1111_110x 10xx_xxxx 10xx_xxxx 10xx_xxxx 10xx_xxxx 10xx_xxxx
-+ return 6;
-+ throw std::runtime_error("The utf8 first char in sequence is incorrect");
-+ }
-+
-+ template<typename ReadFn>
-+ static uint32_t read(ReadFn && read_fn)
-+ {
-+ char_type const ch0 = read_fn();
-+ if (ch0 < 0x80) // 0xxx_xxxx
-+ return ch0;
-+ if (ch0 < 0xC0)
-+ throw std::runtime_error("The utf8 first char in sequence is incorrect");
-+ if (ch0 < 0xE0) // 110x_xxxx 10xx_xxxx
-+ {
-+ char_type const ch1 = read_fn(); if (ch1 >> 6 != 2) goto _err;
-+ return (ch0 << 6) + ch1 - 0x3080;
-+ }
-+ if (ch0 < 0xF0) // 1110_xxxx 10xx_xxxx 10xx_xxxx
-+ {
-+ char_type const ch1 = read_fn(); if (ch1 >> 6 != 2) goto _err;
-+ char_type const ch2 = read_fn(); if (ch2 >> 6 != 2) goto _err;
-+ return (ch0 << 12) + (ch1 << 6) + ch2 - 0xE2080;
-+ }
-+ if (ch0 < 0xF8) // 1111_0xxx 10xx_xxxx 10xx_xxxx 10xx_xxxx
-+ {
-+ char_type const ch1 = read_fn(); if (ch1 >> 6 != 2) goto _err;
-+ char_type const ch2 = read_fn(); if (ch2 >> 6 != 2) goto _err;
-+ char_type const ch3 = read_fn(); if (ch3 >> 6 != 2) goto _err;
-+ return (ch0 << 18) + (ch1 << 12) + (ch2 << 6) + ch3 - 0x3C82080;
-+ }
-+ if (ch0 < 0xFC) // 1111_10xx 10xx_xxxx 10xx_xxxx 10xx_xxxx 10xx_xxxx
-+ {
-+ char_type const ch1 = read_fn(); if (ch1 >> 6 != 2) goto _err;
-+ char_type const ch2 = read_fn(); if (ch2 >> 6 != 2) goto _err;
-+ char_type const ch3 = read_fn(); if (ch3 >> 6 != 2) goto _err;
-+ char_type const ch4 = read_fn(); if (ch4 >> 6 != 2) goto _err;
-+ return (ch0 << 24) + (ch1 << 18) + (ch2 << 12) + (ch3 << 6) + ch4 - 0xFA082080;
-+ }
-+ if (ch0 < 0xFE) // 1111_110x 10xx_xxxx 10xx_xxxx 10xx_xxxx 10xx_xxxx 10xx_xxxx
-+ {
-+ char_type const ch1 = read_fn(); if (ch1 >> 6 != 2) goto _err;
-+ char_type const ch2 = read_fn(); if (ch2 >> 6 != 2) goto _err;
-+ char_type const ch3 = read_fn(); if (ch3 >> 6 != 2) goto _err;
-+ char_type const ch4 = read_fn(); if (ch4 >> 6 != 2) goto _err;
-+ char_type const ch5 = read_fn(); if (ch5 >> 6 != 2) goto _err;
-+ return (ch0 << 30) + (ch1 << 24) + (ch2 << 18) + (ch3 << 12) + (ch4 << 6) + ch5 - 0x82082080;
-+ }
-+ throw std::runtime_error("The utf8 first char in sequence is incorrect");
-+ _err: throw std::runtime_error("The utf8 slave char in sequence is incorrect");
-+ }
-+
-+ template<typename WriteFn>
-+ static void write(uint32_t const cp, WriteFn && write_fn)
-+ {
-+ if (cp < 0x80) // 0xxx_xxxx
-+ write_fn(static_cast<char_type>(cp));
-+ else if (cp < 0x800) // 110x_xxxx 10xx_xxxx
-+ {
-+ write_fn(static_cast<char_type>(0xC0 | cp >> 6));
-+ goto _1;
-+ }
-+ else if (cp < 0x10000) // 1110_xxxx 10xx_xxxx 10xx_xxxx
-+ {
-+ write_fn(static_cast<char_type>(0xE0 | cp >> 12));
-+ goto _2;
-+ }
-+ else if (cp < 0x200000) // 1111_0xxx 10xx_xxxx 10xx_xxxx 10xx_xxxx
-+ {
-+ write_fn(static_cast<char_type>(0xF0 | cp >> 18));
-+ goto _3;
-+ }
-+ else if (cp < 0x4000000) // 1111_10xx 10xx_xxxx 10xx_xxxx 10xx_xxxx 10xx_xxxx
-+ {
-+ write_fn(static_cast<char_type>(0xF8 | cp >> 24));
-+ goto _4;
-+ }
-+ else if (cp < 0x80000000) // 1111_110x 10xx_xxxx 10xx_xxxx 10xx_xxxx 10xx_xxxx 10xx_xxxx
-+ {
-+ write_fn(static_cast<char_type>(0xFC | cp >> 30));
-+ goto _5;
-+ }
-+ else
-+ throw std::runtime_error("Tool large UTF8 code point");
-+ return;
-+ _5: write_fn(static_cast<char_type>(0x80 | (cp >> 24 & 0x3F)));
-+ _4: write_fn(static_cast<char_type>(0x80 | (cp >> 18 & 0x3F)));
-+ _3: write_fn(static_cast<char_type>(0x80 | (cp >> 12 & 0x3F)));
-+ _2: write_fn(static_cast<char_type>(0x80 | (cp >> 6 & 0x3F)));
-+ _1: write_fn(static_cast<char_type>(0x80 | (cp & 0x3F)));
-+ }
-+};
-+
-+}}
-diff --git a/src/ww898/cp_utfw.hpp b/src/ww898/cp_utfw.hpp
-new file mode 100644
-index 000000000..b137d1d5c
---- /dev/null
-+++ b/src/ww898/cp_utfw.hpp
-@@ -0,0 +1,47 @@
-+/*
-+ * MIT License
-+ *
-+ * Copyright (c) 2017-2019 Mikhail Pilin
-+ *
-+ * Permission is hereby granted, free of charge, to any person obtaining a copy
-+ * of this software and associated documentation files (the "Software"), to deal
-+ * in the Software without restriction, including without limitation the rights
-+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-+ * copies of the Software, and to permit persons to whom the Software is
-+ * furnished to do so, subject to the following conditions:
-+ *
-+ * The above copyright notice and this permission notice shall be included in all
-+ * copies or substantial portions of the Software.
-+ *
-+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-+ * SOFTWARE.
-+ */
-+
-+#pragma once
-+
-+#if defined(_WIN32)
-+
-+#include <ww898/cp_utf16.hpp>
-+
-+namespace ww898 {
-+namespace utf {
-+using utfw = utf16;
-+}}
-+
-+#elif defined(__linux__) || defined(__APPLE__)
-+
-+#include <ww898/cp_utf32.hpp>
-+
-+namespace ww898 {
-+namespace utf {
-+using utfw = utf32;
-+}}
-+
-+#else
-+#error Unsupported platform
-+#endif
-diff --git a/src/ww898/url.md b/src/ww898/url.md
-new file mode 100644
-index 000000000..98e6d63ee
---- /dev/null
-+++ b/src/ww898/url.md
-@@ -0,0 +1 @@
-+https://github.com/ww898/utf-cpp/releases/tag/v2.2.1
-\ No newline at end of file
-diff --git a/src/ww898/utf_config.hpp b/src/ww898/utf_config.hpp
-new file mode 100644
-index 000000000..7b4c6c88a
---- /dev/null
-+++ b/src/ww898/utf_config.hpp
-@@ -0,0 +1,41 @@
-+/*
-+ * MIT License
-+ *
-+ * Copyright (c) 2017-2019 Mikhail Pilin
-+ *
-+ * Permission is hereby granted, free of charge, to any person obtaining a copy
-+ * of this software and associated documentation files (the "Software"), to deal
-+ * in the Software without restriction, including without limitation the rights
-+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-+ * copies of the Software, and to permit persons to whom the Software is
-+ * furnished to do so, subject to the following conditions:
-+ *
-+ * The above copyright notice and this permission notice shall be included in all
-+ * copies or substantial portions of the Software.
-+ *
-+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-+ * SOFTWARE.
-+ */
-+
-+#pragma once
-+
-+// Normally `__cpp_lib_string_view` should be defined in string header
-+#include <string>
-+
-+#if !defined(__cpp_lib_string_view)
-+#if defined(_MSVC_LANG)
-+#define __cpp_lib_string_view _MSVC_LANG
-+#else
-+#define __cpp_lib_string_view __cplusplus
-+#endif
-+#endif
-+
-+namespace ww898 {
-+namespace utf {
-+static uint32_t const max_unicode_code_point = 0x10FFFF;
-+}}
-diff --git a/src/ww898/utf_converters.hpp b/src/ww898/utf_converters.hpp
-new file mode 100644
-index 000000000..06088f64d
---- /dev/null
-+++ b/src/ww898/utf_converters.hpp
-@@ -0,0 +1,256 @@
-+/*
-+ * MIT License
-+ *
-+ * Copyright (c) 2017-2019 Mikhail Pilin
-+ *
-+ * Permission is hereby granted, free of charge, to any person obtaining a copy
-+ * of this software and associated documentation files (the "Software"), to deal
-+ * in the Software without restriction, including without limitation the rights
-+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-+ * copies of the Software, and to permit persons to whom the Software is
-+ * furnished to do so, subject to the following conditions:
-+ *
-+ * The above copyright notice and this permission notice shall be included in all
-+ * copies or substantial portions of the Software.
-+ *
-+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-+ * SOFTWARE.
-+ */
-+
-+#pragma once
-+
-+#include <ww898/utf_selector.hpp>
-+#include <ww898/utf_config.hpp>
-+
-+#include <cstdint>
-+#include <iterator>
-+#include <string>
-+
-+#if __cpp_lib_string_view >= 201606
-+#include <string_view>
-+#endif
-+
-+namespace ww898 {
-+namespace utf {
-+
-+namespace detail {
-+
-+enum struct convz_impl { normal, binary_copy };
-+
-+template<
-+ typename Utf,
-+ typename Outf,
-+ typename It,
-+ typename Oit,
-+ convz_impl>
-+struct convz_strategy
-+{
-+ Oit operator()(It it, Oit oit) const
-+ {
-+ auto const read_fn = [&it] { return *it++; };
-+ auto const write_fn = [&oit] (typename Outf::char_type const ch) { *oit++ = ch; };
-+ while (true)
-+ {
-+ auto const cp = Utf::read(read_fn);
-+ if (!cp)
-+ return oit;
-+ Outf::write(cp, write_fn);
-+ }
-+ }
-+};
-+
-+template<
-+ typename Utf,
-+ typename Outf,
-+ typename It,
-+ typename Oit>
-+struct convz_strategy<Utf, Outf, It, Oit, convz_impl::binary_copy>
-+{
-+ Oit operator()(It it, Oit oit) const
-+ {
-+ while (true)
-+ {
-+ auto const ch = *it++;
-+ if (!ch)
-+ return oit;
-+ *oit++ = ch;
-+ }
-+ }
-+};
-+
-+}
-+
-+template<
-+ typename Utf,
-+ typename Outf,
-+ typename It,
-+ typename Oit>
-+Oit convz(It && it, Oit && oit)
-+{
-+ return detail::convz_strategy<Utf, Outf,
-+ typename std::decay<It>::type,
-+ typename std::decay<Oit>::type,
-+ std::is_same<Utf, Outf>::value
-+ ? detail::convz_impl::binary_copy
-+ : detail::convz_impl::normal>()(
-+ std::forward<It>(it),
-+ std::forward<Oit>(oit));
-+}
-+
-+namespace detail {
-+
-+enum struct conv_impl { normal, random_interator, binary_copy };
-+
-+template<
-+ typename Utf,
-+ typename Outf,
-+ typename It,
-+ typename Oit,
-+ conv_impl>
-+struct conv_strategy final
-+{
-+ Oit operator()(It it, It const eit, Oit oit) const
-+ {
-+ auto const read_fn = [&it, &eit]
-+ {
-+ if (it == eit)
-+ throw std::runtime_error("Not enough input");
-+ return *it++;
-+ };
-+ auto const write_fn = [&oit] (typename Outf::char_type const ch) { *oit++ = ch; };
-+ while (it != eit)
-+ Outf::write(Utf::read(read_fn), write_fn);
-+ return oit;
-+ }
-+};
-+
-+template<
-+ typename Utf,
-+ typename Outf,
-+ typename It,
-+ typename Oit>
-+struct conv_strategy<Utf, Outf, It, Oit, conv_impl::random_interator> final
-+{
-+ Oit operator()(It it, It const eit, Oit oit) const
-+ {
-+ auto const write_fn = [&oit] (typename Outf::char_type const ch) { *oit++ = ch; };
-+ if (eit - it >= static_cast<typename std::iterator_traits<It>::difference_type>(Utf::max_supported_symbol_size))
-+ {
-+ auto const fast_read_fn = [&it] { return *it++; };
-+ auto const fast_eit = eit - Utf::max_supported_symbol_size;
-+ while (it < fast_eit)
-+ Outf::write(Utf::read(fast_read_fn), write_fn);
-+ }
-+ auto const read_fn = [&it, &eit]
-+ {
-+ if (it == eit)
-+ throw std::runtime_error("Not enough input");
-+ return *it++;
-+ };
-+ while (it != eit)
-+ Outf::write(Utf::read(read_fn), write_fn);
-+ return oit;
-+ }
-+};
-+
-+template<
-+ typename Utf,
-+ typename Outf,
-+ typename It,
-+ typename Oit>
-+struct conv_strategy<Utf, Outf, It, Oit, conv_impl::binary_copy> final
-+{
-+ Oit operator()(It it, It const eit, Oit oit) const
-+ {
-+ while (it != eit)
-+ *oit++ = *it++;
-+ return oit;
-+ }
-+};
-+
-+}
-+
-+template<
-+ typename Utf,
-+ typename Outf,
-+ typename It,
-+ typename Eit,
-+ typename Oit>
-+Oit conv(It && it, Eit && eit, Oit && oit)
-+{
-+ return detail::conv_strategy<Utf, Outf,
-+ typename std::decay<It>::type,
-+ typename std::decay<Oit>::type,
-+ std::is_same<Utf, Outf>::value
-+ ? detail::conv_impl::binary_copy
-+ : std::is_base_of<std::random_access_iterator_tag, typename std::iterator_traits<typename std::decay<It>::type>::iterator_category>::value
-+ ? detail::conv_impl::random_interator
-+ : detail::conv_impl::normal>()(
-+ std::forward<It>(it),
-+ std::forward<Eit>(eit),
-+ std::forward<Oit>(oit));
-+}
-+
-+template<
-+ typename Outf,
-+ typename Ch,
-+ typename Oit>
-+Oit convz(Ch const * const str, Oit && oit)
-+{
-+ return convz<utf_selector_t<Ch>, Outf>(str, std::forward<Oit>(oit));
-+}
-+
-+template<
-+ typename Och,
-+ typename Str>
-+std::basic_string<Och> convz(Str && str)
-+{
-+ std::basic_string<Och> res;
-+ convz<utf_selector_t<Och>>(std::forward<Str>(str), std::back_inserter(res));
-+ return res;
-+}
-+
-+template<
-+ typename Outf,
-+ typename Ch,
-+ typename Oit>
-+Oit conv(std::basic_string<Ch> const & str, Oit && oit)
-+{
-+ return conv<utf_selector_t<Ch>, Outf>(str.cbegin(), str.cend(), std::forward<Oit>(oit));
-+}
-+
-+#if __cpp_lib_string_view >= 201606
-+template<
-+ typename Outf,
-+ typename Ch,
-+ typename Oit>
-+Oit conv(std::basic_string_view<Ch> const & str, Oit && oit)
-+{
-+ return conv<utf_selector_t<Ch>, Outf>(str.cbegin(), str.cend(), std::forward<Oit>(oit));
-+}
-+#endif
-+
-+template<
-+ typename Och,
-+ typename Str,
-+ typename std::enable_if<!std::is_same<typename std::decay<Str>::type, std::basic_string<Och>>::value, void *>::type = nullptr>
-+std::basic_string<Och> conv(Str && str)
-+{
-+ std::basic_string<Och> res;
-+ conv<utf_selector_t<Och>>(std::forward<Str>(str), std::back_inserter(res));
-+ return res;
-+}
-+
-+template<
-+ typename Ch>
-+std::basic_string<Ch> conv(std::basic_string<Ch> str) throw()
-+{
-+ return str;
-+}
-+
-+}}
-diff --git a/src/ww898/utf_selector.hpp b/src/ww898/utf_selector.hpp
-new file mode 100644
-index 000000000..72302cb58
---- /dev/null
-+++ b/src/ww898/utf_selector.hpp
-@@ -0,0 +1,54 @@
-+/*
-+ * MIT License
-+ *
-+ * Copyright (c) 2017-2019 Mikhail Pilin
-+ *
-+ * Permission is hereby granted, free of charge, to any person obtaining a copy
-+ * of this software and associated documentation files (the "Software"), to deal
-+ * in the Software without restriction, including without limitation the rights
-+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-+ * copies of the Software, and to permit persons to whom the Software is
-+ * furnished to do so, subject to the following conditions:
-+ *
-+ * The above copyright notice and this permission notice shall be included in all
-+ * copies or substantial portions of the Software.
-+ *
-+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-+ * SOFTWARE.
-+ */
-+
-+#pragma once
-+
-+#include <ww898/cp_utf8.hpp>
-+#include <ww898/cp_utf16.hpp>
-+#include <ww898/cp_utf32.hpp>
-+#include <ww898/cp_utfw.hpp>
-+
-+namespace ww898 {
-+namespace utf {
-+namespace detail {
-+
-+template<typename Ch>
-+struct utf_selector final {};
-+
-+template<> struct utf_selector< char> final { using type = utf8 ; };
-+template<> struct utf_selector<unsigned char> final { using type = utf8 ; };
-+template<> struct utf_selector<signed char> final { using type = utf8 ; };
-+template<> struct utf_selector<char16_t > final { using type = utf16; };
-+template<> struct utf_selector<char32_t > final { using type = utf32; };
-+template<> struct utf_selector<wchar_t > final { using type = utfw ; };
-+
-+}
-+
-+template<typename Ch>
-+using utf_selector = detail::utf_selector<typename std::decay<Ch>::type>;
-+
-+template<typename Ch>
-+using utf_selector_t = typename utf_selector<Ch>::type;
-+
-+}}
-diff --git a/src/ww898/utf_sizes.hpp b/src/ww898/utf_sizes.hpp
-new file mode 100644
-index 000000000..a370cc9f0
---- /dev/null
-+++ b/src/ww898/utf_sizes.hpp
-@@ -0,0 +1,136 @@
-+/*
-+ * MIT License
-+ *
-+ * Copyright (c) 2017-2019 Mikhail Pilin
-+ *
-+ * Permission is hereby granted, free of charge, to any person obtaining a copy
-+ * of this software and associated documentation files (the "Software"), to deal
-+ * in the Software without restriction, including without limitation the rights
-+ * to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
-+ * copies of the Software, and to permit persons to whom the Software is
-+ * furnished to do so, subject to the following conditions:
-+ *
-+ * The above copyright notice and this permission notice shall be included in all
-+ * copies or substantial portions of the Software.
-+ *
-+ * THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
-+ * IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
-+ * FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
-+ * AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
-+ * LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
-+ * OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
-+ * SOFTWARE.
-+ */
-+
-+#pragma once
-+
-+#include <ww898/utf_selector.hpp>
-+#include <ww898/utf_config.hpp>
-+
-+#include <cstddef>
-+#include <iterator>
-+#include <string>
-+
-+#if __cpp_lib_string_view >= 201606
-+#include <string_view>
-+#endif
-+
-+namespace ww898 {
-+namespace utf {
-+
-+template<
-+ typename Utf,
-+ typename It>
-+size_t char_size(It it)
-+{
-+ return Utf::char_size([&it] { return *it; });
-+}
-+
-+template<
-+ typename Utf,
-+ typename It>
-+size_t size(It it)
-+{
-+ size_t total_cp = 0;
-+ while (*it)
-+ {
-+ size_t size = Utf::char_size([&it] { return *it; });
-+ while (++it, --size > 0)
-+ if (!*it)
-+ throw std::runtime_error("Not enough input for the null-terminated string");
-+ ++total_cp;
-+ }
-+ return total_cp;
-+}
-+
-+namespace detail {
-+
-+enum struct iterator_impl { forward, random_access };
-+
-+template<
-+ typename It,
-+ iterator_impl>
-+struct next_strategy final
-+{
-+ void operator()(It & it, It const & eit, size_t size)
-+ {
-+ while (++it, --size > 0)
-+ if (it == eit)
-+ throw std::runtime_error("Not enough input for the forward iterator");
-+ }
-+};
-+
-+template<typename It>
-+struct next_strategy<It, iterator_impl::random_access> final
-+{
-+ void operator()(It & it, It const & eit, typename std::iterator_traits<It>::difference_type const size)
-+ {
-+ if (eit - it < size)
-+ throw std::runtime_error("Not enough input for the random access iterator");
-+ it += size;
-+ }
-+};
-+
-+}
-+
-+template<
-+ typename Utf,
-+ typename It,
-+ typename Eit>
-+size_t size(It it, Eit const eit)
-+{
-+ size_t total_cp = 0;
-+ while (it != eit)
-+ {
-+ size_t const size = Utf::char_size([&it] { return *it; });
-+ detail::next_strategy<
-+ typename std::decay<It>::type,
-+ std::is_base_of<std::random_access_iterator_tag, typename std::iterator_traits<typename std::decay<It>::type>::iterator_category>::value
-+ ? detail::iterator_impl::random_access
-+ : detail::iterator_impl::forward>()(it, eit, size);
-+ ++total_cp;
-+ }
-+ return total_cp;
-+}
-+
-+template<typename Ch>
-+size_t size(Ch const * str)
-+{
-+ return size<utf_selector_t<Ch>>(str);
-+}
-+
-+template<typename Ch>
-+size_t size(std::basic_string<Ch> str)
-+{
-+ return size<utf_selector_t<Ch>>(str.cbegin(), str.cend());
-+}
-+
-+#if __cpp_lib_string_view >= 201606
-+template<typename Ch>
-+size_t size(std::basic_string_view<Ch> str)
-+{
-+ return size<utf_selector_t<Ch>>(str.cbegin(), str.cend());
-+}
-+#endif
-+
-+}}
-
-From e929a8b600e9a459cd0b411d50f4570595eab203 Mon Sep 17 00:00:00 2001
-From: Kuba Ober <kuba at bertec.com>
-Date: Sat, 28 Nov 2020 01:15:16 -0500
-Subject: [PATCH 2/4] Make utf-cpp not throw.
-
----
- src/ww898/cp_utf16.hpp | 20 ++++++++++++++------
- src/ww898/cp_utf32.hpp | 9 ++++++---
- src/ww898/cp_utf8.hpp | 21 ++++++++++++++-------
- 3 files changed, 34 insertions(+), 16 deletions(-)
-
-diff --git a/src/ww898/cp_utf16.hpp b/src/ww898/cp_utf16.hpp
-index 2e1134974..d310f272e 100644
---- a/src/ww898/cp_utf16.hpp
-+++ b/src/ww898/cp_utf16.hpp
-@@ -25,7 +25,7 @@
- #pragma once
-
- #include <cstdint>
--#include <stdexcept>
-+#include <utility>
-
- namespace ww898 {
- namespace utf {
-@@ -40,6 +40,7 @@ struct utf16 final
- static size_t const max_unicode_symbol_size = 2;
- static size_t const max_supported_symbol_size = max_unicode_symbol_size;
-
-+ static uint32_t const invalid_code_point = -1;
- static uint32_t const max_supported_code_point = 0x10FFFF;
-
- using char_type = uint16_t;
-@@ -62,7 +63,8 @@ struct utf16 final
- if (ch0 < 0xDC00) // [0xD800‥0xDBFF] [0xDC00‥0xDFFF]
- return 2;
- if (ch0 < 0xE000)
-- throw std::runtime_error("The high utf16 surrogate char is expected");
-+ return 1;
-+ //throw std::runtime_error("The high utf16 surrogate char is expected");
- // [0xE000‥0xFFFF]
- return 1;
- }
-@@ -75,11 +77,15 @@ struct utf16 final
- return ch0;
- if (ch0 < 0xDC00) // [0xD800‥0xDBFF] [0xDC00‥0xDFFF]
- {
-- char_type const ch1 = read_fn(); if (ch1 >> 10 != 0x37) throw std::runtime_error("The low utf16 surrogate char is expected");
-+ char_type const ch1 = read_fn();
-+ if (ch1 >> 10 != 0x37)
-+ return invalid_code_point;
-+ //throw std::runtime_error("The low utf16 surrogate char is expected");
- return (ch0 << 10) + ch1 - 0x35FDC00;
- }
- if (ch0 < 0xE000)
-- throw std::runtime_error("The high utf16 surrogate char is expected");
-+ return invalid_code_point;
-+ //throw std::runtime_error("The high utf16 surrogate char is expected");
- // [0xE000‥0xFFFF]
- return ch0;
- }
-@@ -92,7 +98,8 @@ struct utf16 final
- else if (cp < 0x10000)
- {
- if (cp < 0xE000)
-- throw std::runtime_error("The utf16 code point can not be in surrogate range");
-+ return;
-+ //throw std::runtime_error("The utf16 code point can not be in surrogate range");
- // [0xE000‥0xFFFF]
- write_fn(static_cast<char_type>(cp));
- }
-@@ -102,7 +109,8 @@ struct utf16 final
- write_fn(static_cast<char_type>(0xDC00 + (cp & 0x3FF)));
- }
- else
-- throw std::runtime_error("Too large the utf16 code point");
-+ return;
-+ // throw std::runtime_error("Too large the utf16 code point");
- }
- };
-
-diff --git a/src/ww898/cp_utf32.hpp b/src/ww898/cp_utf32.hpp
-index 90b11fad7..6e0a84bbb 100644
---- a/src/ww898/cp_utf32.hpp
-+++ b/src/ww898/cp_utf32.hpp
-@@ -25,7 +25,7 @@
- #pragma once
-
- #include <cstdint>
--#include <stdexcept>
-+#include <utility>
-
- namespace ww898 {
- namespace utf {
-@@ -35,6 +35,7 @@ struct utf32 final
- static size_t const max_unicode_symbol_size = 1;
- static size_t const max_supported_symbol_size = 1;
-
-+ static uint32_t const invalid_code_point = -1;
- static uint32_t const max_supported_code_point = 0x7FFFFFFF;
-
- using char_type = uint32_t;
-@@ -51,7 +52,8 @@ struct utf32 final
- char_type const ch = std::forward<ReadFn>(read_fn)();
- if (ch < 0x80000000)
- return ch;
-- throw std::runtime_error("Too large utf32 char");
-+ return invalid_code_point;
-+ //throw std::runtime_error("Too large utf32 char");
- }
-
- template<typename WriteFn>
-@@ -60,7 +62,8 @@ struct utf32 final
- if (cp < 0x80000000)
- std::forward<WriteFn>(write_fn)(static_cast<char_type>(cp));
- else
-- throw std::runtime_error("Too large utf32 code point");
-+ return;
-+ //throw std::runtime_error("Too large utf32 code point");
- }
- };
-
-diff --git a/src/ww898/cp_utf8.hpp b/src/ww898/cp_utf8.hpp
-index 7c8c68d03..1d4991107 100644
---- a/src/ww898/cp_utf8.hpp
-+++ b/src/ww898/cp_utf8.hpp
-@@ -25,7 +25,7 @@
- #pragma once
-
- #include <cstdint>
--#include <stdexcept>
-+#include <utility>
-
- namespace ww898 {
- namespace utf {
-@@ -42,6 +42,7 @@ struct utf8 final
- static size_t const max_unicode_symbol_size = 4;
- static size_t const max_supported_symbol_size = 6;
-
-+ static uint32_t const invalid_code_point = -1;
- static uint32_t const max_supported_code_point = 0x7FFFFFFF;
-
- using char_type = uint8_t;
-@@ -53,7 +54,8 @@ struct utf8 final
- if (ch0 < 0x80) // 0xxx_xxxx
- return 1;
- if (ch0 < 0xC0)
-- throw std::runtime_error("The utf8 first char in sequence is incorrect");
-+ return 1;
-+ //throw std::runtime_error("The utf8 first char in sequence is incorrect");
- if (ch0 < 0xE0) // 110x_xxxx 10xx_xxxx
- return 2;
- if (ch0 < 0xF0) // 1110_xxxx 10xx_xxxx 10xx_xxxx
-@@ -64,7 +66,8 @@ struct utf8 final
- return 5;
- if (ch0 < 0xFE) // 1111_110x 10xx_xxxx 10xx_xxxx 10xx_xxxx 10xx_xxxx 10xx_xxxx
- return 6;
-- throw std::runtime_error("The utf8 first char in sequence is incorrect");
-+ return 1;
-+ //throw std::runtime_error("The utf8 first char in sequence is incorrect");
- }
-
- template<typename ReadFn>
-@@ -74,7 +77,8 @@ struct utf8 final
- if (ch0 < 0x80) // 0xxx_xxxx
- return ch0;
- if (ch0 < 0xC0)
-- throw std::runtime_error("The utf8 first char in sequence is incorrect");
-+ return invalid_code_point;
-+ //throw std::runtime_error("The utf8 first char in sequence is incorrect");
- if (ch0 < 0xE0) // 110x_xxxx 10xx_xxxx
- {
- char_type const ch1 = read_fn(); if (ch1 >> 6 != 2) goto _err;
-@@ -110,8 +114,10 @@ struct utf8 final
- char_type const ch5 = read_fn(); if (ch5 >> 6 != 2) goto _err;
- return (ch0 << 30) + (ch1 << 24) + (ch2 << 18) + (ch3 << 12) + (ch4 << 6) + ch5 - 0x82082080;
- }
-- throw std::runtime_error("The utf8 first char in sequence is incorrect");
-- _err: throw std::runtime_error("The utf8 slave char in sequence is incorrect");
-+ return invalid_code_point;
-+ //throw std::runtime_error("The utf8 first char in sequence is incorrect");
-+ _err: return invalid_code_point;
-+ //throw std::runtime_error("The utf8 slave char in sequence is incorrect");
- }
-
- template<typename WriteFn>
-@@ -145,7 +151,8 @@ struct utf8 final
- goto _5;
- }
- else
-- throw std::runtime_error("Tool large UTF8 code point");
-+ return;
-+ //throw std::runtime_error("Tool large UTF8 code point");
- return;
- _5: write_fn(static_cast<char_type>(0x80 | (cp >> 24 & 0x3F)));
- _4: write_fn(static_cast<char_type>(0x80 | (cp >> 18 & 0x3F)));
-
-From 8a6ea740d62623b5909f37e9c3330c8bd3e231d0 Mon Sep 17 00:00:00 2001
-From: Kuba Ober <kuba at bertec.com>
-Date: Sat, 28 Nov 2020 01:39:06 -0500
-Subject: [PATCH 3/4] Fix file formatting comment.
-
----
- src/StreamUtils.h | 3 +--
- 1 file changed, 1 insertion(+), 2 deletions(-)
-
-diff --git a/src/StreamUtils.h b/src/StreamUtils.h
-index ab75091ae..9abc9a6ae 100644
---- a/src/StreamUtils.h
-+++ b/src/StreamUtils.h
-@@ -1,5 +1,4 @@
--// -*- mode: c++; c-file-style: "linux"; c-basic-offset: 2; indent-tabs-mode:
--// nil -*-
-+// -*- mode: c++; c-file-style: "linux"; c-basic-offset: 2; indent-tabs-mode: nil -*-
- //
- // Copyright (C) 2020 Kuba Ober <kuba at mareimbrium.org>
- //
-
-From 7b768c3eed195f9bcb2a64fcfef8057a20af89ef Mon Sep 17 00:00:00 2001
-From: Kuba Ober <kuba at bertec.com>
-Date: Sat, 28 Nov 2020 02:28:22 -0500
-Subject: [PATCH 4/4] Reimplement the UTF8Decoder using utf-cpp.
-
----
- src/StreamUtils.cpp | 84 ++++++++++++++++++++++++++-------------------
- src/StreamUtils.h | 29 +++++-----------
- 2 files changed, 56 insertions(+), 57 deletions(-)
-
-diff --git a/src/StreamUtils.cpp b/src/StreamUtils.cpp
-index edd342a99..f1aefc917 100644
---- a/src/StreamUtils.cpp
-+++ b/src/StreamUtils.cpp
-@@ -51,29 +51,15 @@
- // SPDX-License-Identifier: wxWindows
-
- #include "StreamUtils.h"
--#include <wx/stream.h>
--#include <algorithm>
-+#include "ww898/utf_selector.hpp"
- #include <cstring>
-+#include <wx/stream.h>
-+#include <wx/log.h>
-
--UTF8Decoder::UTF8Decoder()
--#if !(defined(__WINDOWS__) && wxUSE_UNICODE)
-- // This works on newer Windows 10, but fails on older Windows,
-- // thus we fall back to the deprecated utf8 codec.
-- : m_locale("en_US.UTF8"),
-- m_codec(std::use_facet<std::remove_reference<decltype(m_codec)>::type>(m_locale))
--#endif
--{
--}
--
--UTF8Decoder::DecodeResult UTF8Decoder::Decode(UTF8Decoder::State &state,
-- wxInputStream &in, size_t maxRead,
-- size_t maxWrite)
--{
-- return state.Decode(m_codec, in, maxRead, maxWrite);
--}
-+using utf8 = ww898::utf::utf8;
-+using utfwx = ww898::utf::utf_selector_t<wxStringCharType>;
-
--UTF8Decoder::DecodeResult UTF8Decoder::State::Decode(const Codec &codec,
-- wxInputStream &in,
-+UTF8Decoder::DecodeResult UTF8Decoder::State::Decode(wxInputStream &in,
- size_t maxRead,
- size_t maxWrite)
- {
-@@ -94,25 +80,49 @@ UTF8Decoder::DecodeResult UTF8Decoder::State::Decode(const Codec &codec,
- if (m_outBuf.size() < maxWrite)
- m_outBuf.resize(maxWrite);
-
-- // Decode
-+ // Transcode
- auto const *inPtr = m_inBuf.data();
- auto *outPtr = m_outBuf.data();
-
-- auto const dr = codec.in(m_codecState, inPtr, inPtr + m_inBufCount, inPtr,
-- outPtr, outPtr + m_outBuf.size(), outPtr);
-+ size_t const inLengthBeforeCheckpoint =
-+ (m_inBufCount >= utf8::max_supported_symbol_size) ?
-+ m_inBufCount - (utf8::max_supported_symbol_size - 1): 0;
-
-- // Fallback for noconv
-- if (dr == std::codecvt_base::noconv)
-- {
-- wxASSERT(inPtr == m_inBuf.data() && outPtr == m_outBuf.data());
-- auto toCopy = std::min(m_inBufCount, m_outBuf.size());
-- std::copy(inPtr, inPtr+toCopy, outPtr);
-- inPtr += toCopy;
-- outPtr += toCopy;
-- }
-- else if (dr == std::codecvt_base::error)
-- {
-- m_hadError = true;
-+ size_t const outLengthBeforeCheckpoint =
-+ (maxWrite >= utfwx::max_supported_symbol_size) ?
-+ maxWrite - (utfwx::max_supported_symbol_size - 1): 0;
-+
-+ auto const *const inCheckpoint = inPtr + inLengthBeforeCheckpoint;
-+ auto const *const inEnd = inPtr + m_inBufCount;
-+ auto *const outCheckpoint = outPtr + outLengthBeforeCheckpoint;
-+ auto *const outEnd = outPtr + m_outBuf.size();
-+ bool hadError = false;
-+
-+ for (;;) {
-+ // Decode utf8
-+ if (inPtr >= inCheckpoint) {
-+ if (inPtr == inEnd)
-+ break;
-+ auto const size = utf8::char_size([=]{ return *inPtr; });
-+ if (ptrdiff_t(size) > (inEnd - inPtr))
-+ break;
-+ }
-+ auto const *const prevInPtr = inPtr;
-+ auto const cp = utf8::read([&]{ return *inPtr++; });
-+ if (cp == utf8::invalid_code_point) {
-+ hadError = true;
-+ continue;
-+ }
-+
-+ // Encode based on wxStringCharType
-+ if (outPtr >= outCheckpoint) {
-+ auto const size = utfwx::char_size([=]{ return cp; });
-+ if (ptrdiff_t(size) > (outEnd - outPtr)) { // we've ran out of write space
-+ inPtr = prevInPtr; // un-read the input data so we won't lose it
-+ break;
-+ }
-+ }
-+ utfwx::write(cp, [&](auto ch){ *outPtr++ = ch; });
- }
-
- auto const outBufCount = outPtr - m_outBuf.data();
-@@ -120,6 +130,8 @@ UTF8Decoder::DecodeResult UTF8Decoder::State::Decode(const Codec &codec,
- // Shove leftover input data to the beginning of the buffer
- auto const inBufPos = inPtr - m_inBuf.data();
- auto const inLeftCount = m_inBufCount - inBufPos;
-+ //std::cout << inBufPos << " " << inLeftCount << std::endl;
-+ wxLogDebug("%lld %lld %lld", inBufPos, m_inBufCount, inLeftCount);
- memmove(m_inBuf.data(), inPtr, inLeftCount);
- m_inBufCount = inLeftCount;
-
-@@ -128,6 +140,6 @@ UTF8Decoder::DecodeResult UTF8Decoder::State::Decode(const Codec &codec,
- result.outputSize = outBufCount;
- result.output = m_outBuf.data();
- result.outputEnd = m_outBuf.data() + outBufCount;
-- result.ok = (dr != std::codecvt_base::error);
-+ result.ok = !hadError;
- return result;
- }
-diff --git a/src/StreamUtils.h b/src/StreamUtils.h
-index 9abc9a6ae..7547c6700 100644
---- a/src/StreamUtils.h
-+++ b/src/StreamUtils.h
-@@ -58,28 +58,15 @@
- * and/or otherwise needed by wxMaxima.
- */
-
--#define _SILENCE_CXX17_CODECVT_HEADER_DEPRECATION_WARNING
- #include <wx/stream.h>
- #include <wx/string.h>
--#include <codecvt>
- #include <vector>
-
- //! A stateful decoder that can feed itself from an input stream and
- //! append its output to a string. Useful in any situation where the
- //! exact amount of data read and written must be controlled.
--class UTF8Decoder {
--#if defined(__WINDOWS__) && wxUSE_UNICODE
-- // Note: The explicit little_endian mode is needed on MinGW builds, otherwise the output is
-- // big-endian and the subsequent decoding and use of it fails. MSVC builds are OK with this
-- // mode explicitly set, or without it.
-- using Codec = std::codecvt_utf8<wxStringCharType, 0x10ffff, std::codecvt_mode::little_endian>;
-- Codec m_codec;
--#else
-- std::locale m_locale;
-- using Codec = std::codecvt<wxStringCharType, char, std::mbstate_t>;
-- const Codec &m_codec;
--#endif
--
-+class UTF8Decoder
-+{
- public:
- struct DecodeResult
- {
-@@ -92,18 +79,18 @@ class UTF8Decoder {
-
- class State
- {
-- std::mbstate_t m_codecState = {};
- std::vector<char> m_inBuf;
- size_t m_inBufCount = {};
- std::vector<wxStringCharType> m_outBuf;
-- bool m_hadError = false;
- public:
-- DecodeResult Decode(const Codec &, wxInputStream &in, size_t maxRead, size_t maxWrite);
-- bool hadError() const { return m_hadError; }
-+ DecodeResult Decode(wxInputStream &in, size_t maxRead, size_t maxWrite);
- };
-
-- UTF8Decoder();
-- DecodeResult Decode(State &state, wxInputStream &in, size_t maxRead, size_t maxWrite);
-+ static DecodeResult Decode(State &state, wxInputStream &in, size_t maxRead,
-+ size_t maxWrite)
-+ {
-+ return state.Decode(in, maxRead, maxWrite);
-+ }
- };
-
- #endif
More information about the arch-commits
mailing list